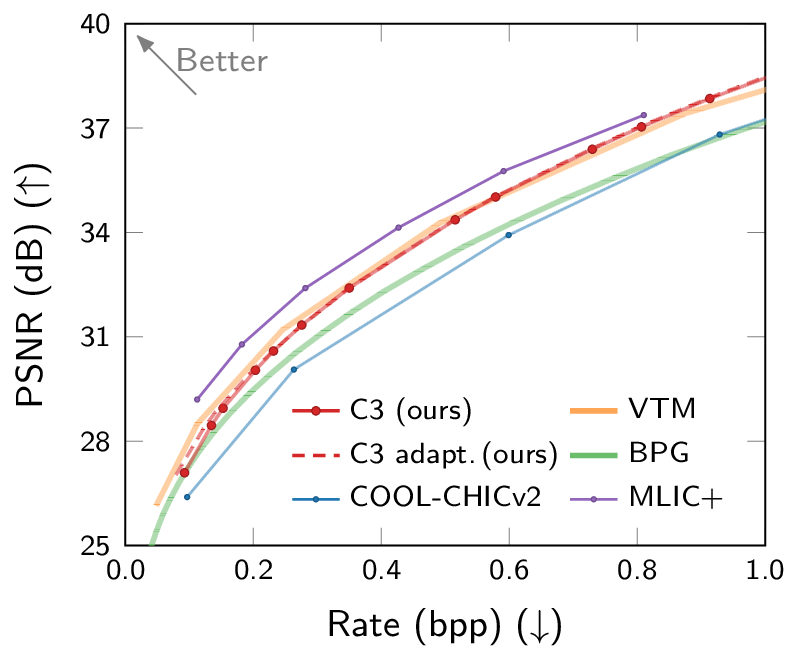
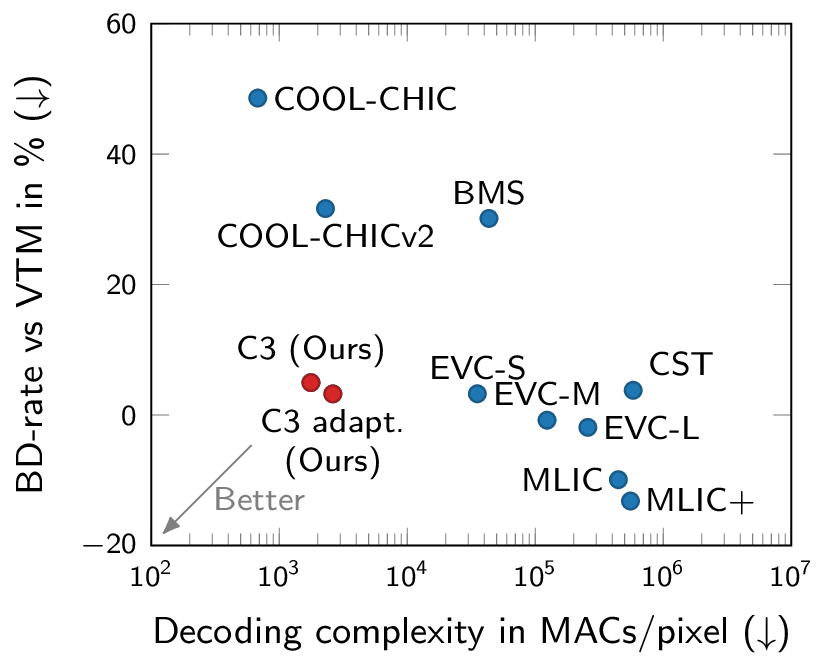
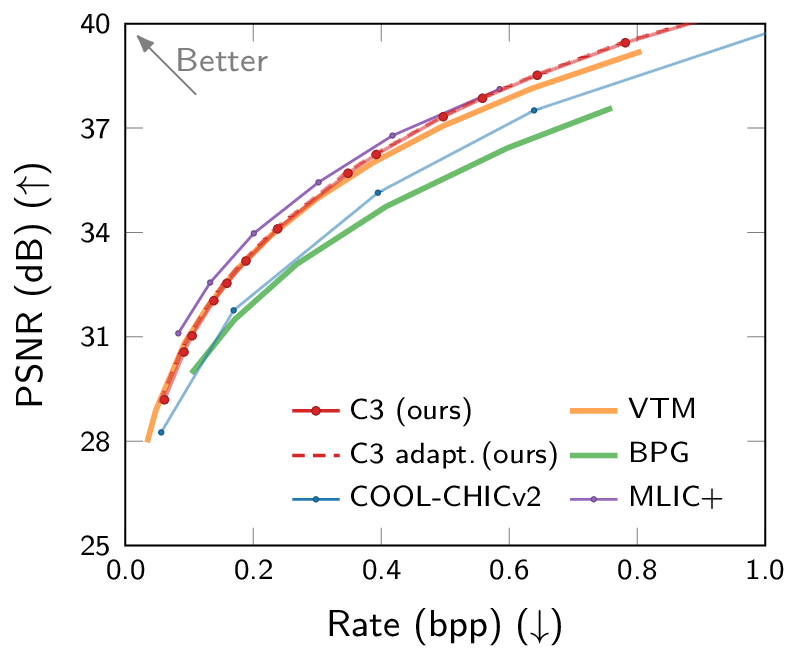
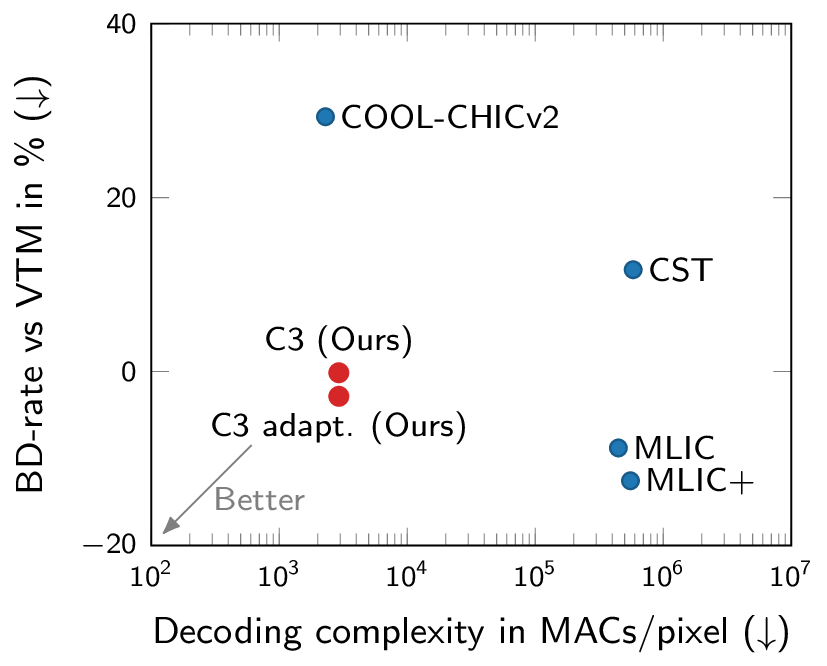
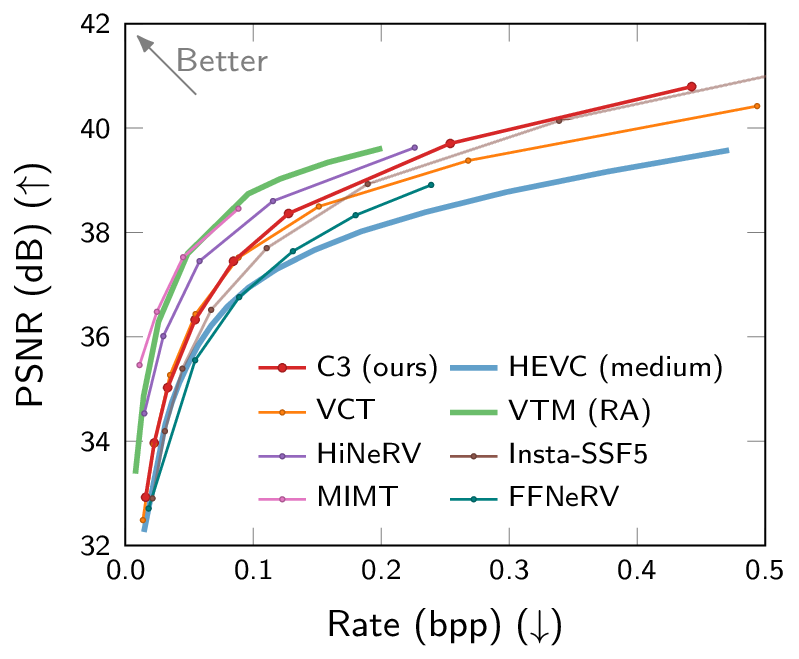
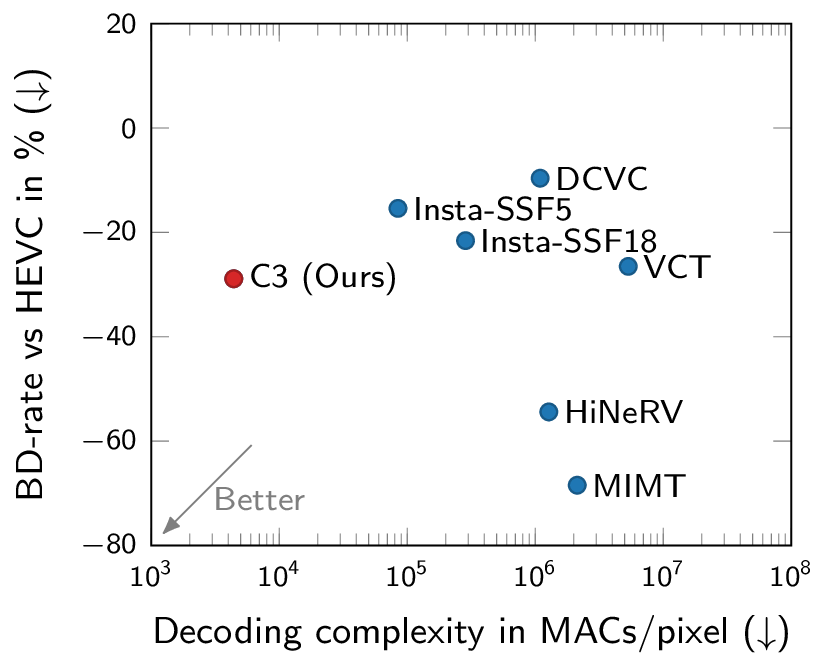
Rate-distortion and computational complexity results. C3 is the first low-complexity neural codec competitive with VTM.
Abstract
Most neural compression models are trained on large datasets of images or videos in order to generalize to unseen data. Such generalization typically requires large and expressive architectures with a high decoding complexity. Here we introduce C3, a neural compression method with strong rate-distortion (RD) performance that instead overfits a small model to each image or video separately. The resulting decoding complexity of C3 can be an order of magnitude lower than neural baselines with similar RD performance. C3 builds on COOL-CHIC (Ladune et al., 2023) and makes several simple and effective improvements for images. We further develop new methodology to apply C3 to videos. On the CLIC2020 image benchmark, we match the RD performance of VTM, the reference implementation of the H.266 codec, with less than 3k MACs/pixel for decoding. On the UVG video benchmark, we match the RD performance of the Video Compression Transformer (Mentzer et al., 2022), a well-established neural video codec, with less than 5k MACs/pixel for decoding.
Method
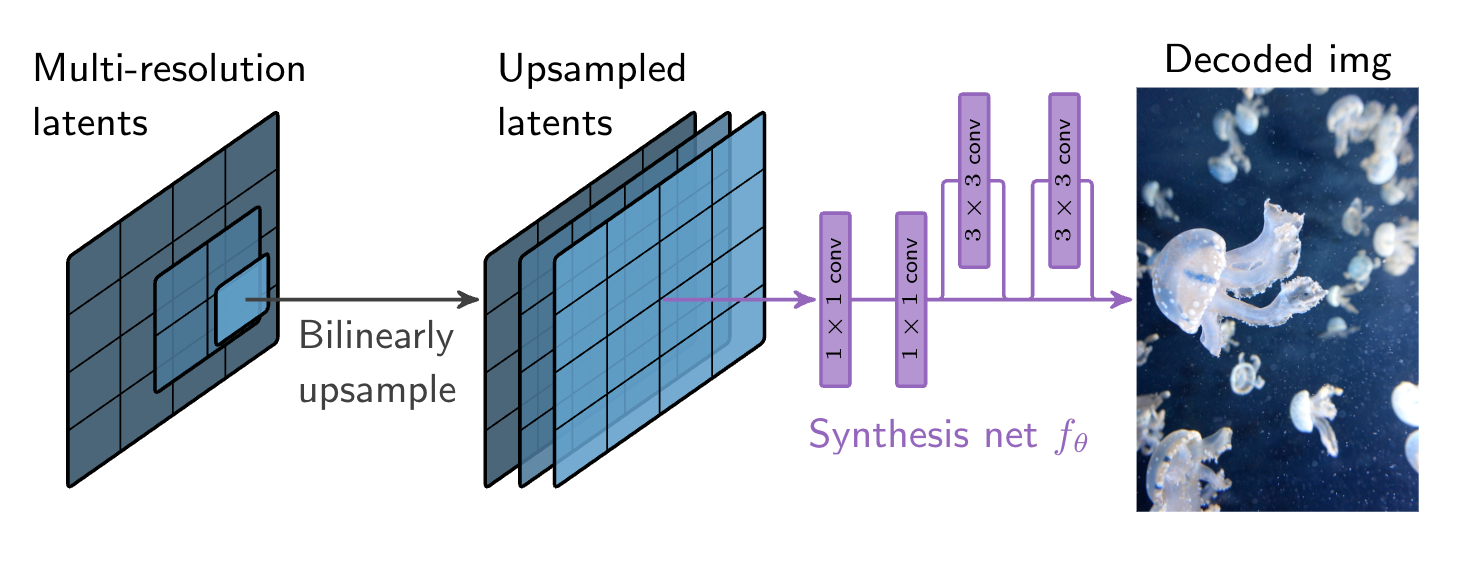
Visualization of the image decoding process.
Following earlier work, the decoder receives compressed latents at multiple resolutions and parameters of a small entropy model as well as parameters of a synthesis network. After decoding latents with the entropy model, the latents are upsampled to the image resolution and passed through the synthesis network. Importantly, the synthesis network, the entropy model, and the latents are optimized on a per-image basis by the encoder.
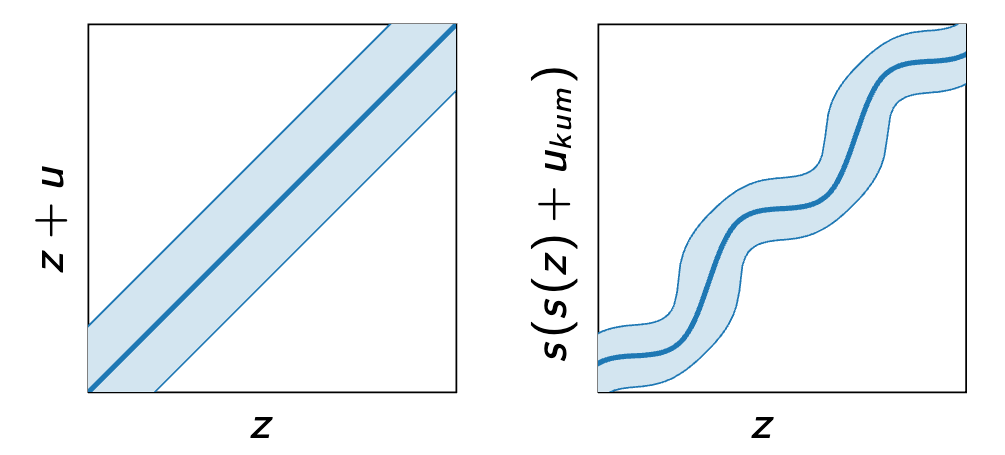
An illustration of uniform noise (left) and soft-rounding plus non-uniform noise (right). Shown are the mean and 95% confidence intervals.
We significantly improve the performance of this approach through better approximations of quantization, different activation functions, and other improvements. In particular, we find that soft-rounding dither is crucial for good performance and that non-uniform quantization noise works better than the uniform noise typically used to approximate quantization.


0.3097 bpp
30.28 dB
0.3097 bpp
17.42 dB
An example image reconstruction compared to JPEG (4:4:4).
We further extended the approach to videos. This is achieved by using 3D (instead of 2D) latents and a novel context selection strategy which enables efficient entropy coding in the presence of fast motion. Larger videos are divided into patches of up to 75 frames and 270x320 pixels, and each patch is compressed independently.
Reconstruction of a video from the UVG dataset (Bosphorus @ 0.05 bpp).
Visualization of latents corresponding to the video above.
Files
Raw quantitative results used in our figures can be downloaded below.
-
Quantitative results
.zip, 5 KB
Citation
@inproceedings{kim2023c3,
title = {C3: High-performance and low-complexity neural compression from a single image or video},
author = {Hyunjik Kim and Matthias Bauer and Lucas Theis and Jonathan Richard Schwarz and Emilien Dupont},
year = {2024},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
}